I may be one of the few developers who actually somewhat enjoy documentation. After all, I don't know about your memory skills, but I can't remember what I had for lunch a week ago, let alone why I designed things the way I did on a software project 9 months ago. In my estimation, the biggest reason projects fail is the lack of communication, which is fostered by good documentation.
Good documentation to me doesn't need to be verbose, just enough to capture what needs to be done and how it will be done. I think most information on a project should be captured in diagrams, and a quick scan of the diagrams should give a quick and concise view of the architecture and design, as well as the functional requirements.
Providing diagrams early in the requirements stage, at least as use cases, provides a great deal of insight into who are the actors interacting with the system, and in what way. A good use case analysis will also lead to the development of test cases to help validate the system so both developers and business users know what to expect from the system. Human actors can be captured generally using their roles in the system, and external systems can also be represented as actors. Having a comprehensive list of user roles and external systems showing which use cases they affect shows the capabilities and expectations of the system. I've used this type of diagram as simple as having 2 tables following the diagram that describe each actor in one table, then the other one describes each use case in a short sentence, possibly even referring back to some project requirements document for tracability. Or you can break out each use case into a full document on its own, and show pre-conditions, post-conditions, a detailed flow of interactions between actors and the system, and alternate flows for cases other than the "happy path".
Many tools allow creation of a use case diagram, and need not be expensive. You can use free tools like ArgoUML, an IDE supporting UML diagrams like Oracle JDeveloper, or use something more commercial like Visio. The point is that as long as it gets documented and everyone buys off on the scope of work for the project, it makes it much more difficult later on for the business team to claim that your code doesn't support test cases that don't trace back to use cases they signed off on.
Monday, April 27, 2009
Oracle BPEL Database Adapter DMLTypes
First of all, I'm not an Oracle software engineer on the BPEL Process Manager product line, but having worked with it for a couple of years, I will at least provide what I think is going on with the DML Types available for use in the database adapter, since I have yet to find a spot where they've documented them clearly.
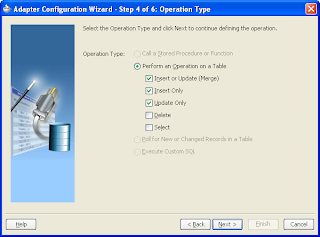 What I'm talking about here are the choices available when creating a database adapter partner link in BPEL using a table operation, not using direct SQL. I think the obvious ones that are well understood are Insert Only, Update Only, Delete and Select. The one not as clearly documented is the Insert or Update option.
What I'm talking about here are the choices available when creating a database adapter partner link in BPEL using a table operation, not using direct SQL. I think the obvious ones that are well understood are Insert Only, Update Only, Delete and Select. The one not as clearly documented is the Insert or Update option.
If you select this option, it creates a WSDL for the partner link that includes a couple of DML (database manipulation language) operations called Write and Merge. The database adapter documentation says it is preferred to use Write over Merge for performance reasons but doesn't elaborate.
 On my current project which integrates to a custom table into Peoplesoft, I first tried using the Write operation in my BPEL process. It would consistently create new records in the table since their isn't a primary key or unique index defined using the true primary keys. I then switched it to Merge, and voila it worked. What I suspect is happening is for Write operations, the adapter attempts to insert the record, and if the database errors out due to unique constraint violation it will automatically try the update operation. So if the table doesn't have a unique constraint for your key set, the Write will not work. Conversely, the Merge operation will look at your toplink mappings file and select using the primary key you define in the wizard, and if a row is returned, will perform an update, otherwise perform an insert. The Merge also supports hierarchical database structures, which I wasn't using it for in this case.
On my current project which integrates to a custom table into Peoplesoft, I first tried using the Write operation in my BPEL process. It would consistently create new records in the table since their isn't a primary key or unique index defined using the true primary keys. I then switched it to Merge, and voila it worked. What I suspect is happening is for Write operations, the adapter attempts to insert the record, and if the database errors out due to unique constraint violation it will automatically try the update operation. So if the table doesn't have a unique constraint for your key set, the Write will not work. Conversely, the Merge operation will look at your toplink mappings file and select using the primary key you define in the wizard, and if a row is returned, will perform an update, otherwise perform an insert. The Merge also supports hierarchical database structures, which I wasn't using it for in this case.
Hopefully this helps understand when and why to use the Write and Merge operations of the Database Adapter. Let me know if my assumptions about the inner workings are correct, as this is written from the perspective of an observer and not an inside developer.
 What I'm talking about here are the choices available when creating a database adapter partner link in BPEL using a table operation, not using direct SQL. I think the obvious ones that are well understood are Insert Only, Update Only, Delete and Select. The one not as clearly documented is the Insert or Update option.
What I'm talking about here are the choices available when creating a database adapter partner link in BPEL using a table operation, not using direct SQL. I think the obvious ones that are well understood are Insert Only, Update Only, Delete and Select. The one not as clearly documented is the Insert or Update option.If you select this option, it creates a WSDL for the partner link that includes a couple of DML (database manipulation language) operations called Write and Merge. The database adapter documentation says it is preferred to use Write over Merge for performance reasons but doesn't elaborate.
 On my current project which integrates to a custom table into Peoplesoft, I first tried using the Write operation in my BPEL process. It would consistently create new records in the table since their isn't a primary key or unique index defined using the true primary keys. I then switched it to Merge, and voila it worked. What I suspect is happening is for Write operations, the adapter attempts to insert the record, and if the database errors out due to unique constraint violation it will automatically try the update operation. So if the table doesn't have a unique constraint for your key set, the Write will not work. Conversely, the Merge operation will look at your toplink mappings file and select using the primary key you define in the wizard, and if a row is returned, will perform an update, otherwise perform an insert. The Merge also supports hierarchical database structures, which I wasn't using it for in this case.
On my current project which integrates to a custom table into Peoplesoft, I first tried using the Write operation in my BPEL process. It would consistently create new records in the table since their isn't a primary key or unique index defined using the true primary keys. I then switched it to Merge, and voila it worked. What I suspect is happening is for Write operations, the adapter attempts to insert the record, and if the database errors out due to unique constraint violation it will automatically try the update operation. So if the table doesn't have a unique constraint for your key set, the Write will not work. Conversely, the Merge operation will look at your toplink mappings file and select using the primary key you define in the wizard, and if a row is returned, will perform an update, otherwise perform an insert. The Merge also supports hierarchical database structures, which I wasn't using it for in this case.Hopefully this helps understand when and why to use the Write and Merge operations of the Database Adapter. Let me know if my assumptions about the inner workings are correct, as this is written from the perspective of an observer and not an inside developer.
Subscribe to:
Posts (Atom)